
Data is the new black gold in business. In this post, we explore how shifts in technology, organization processes, and people are critical to achieving the vision for a data-driven company that deploys data mesh architecture in cloud-based warehouses like Snowflake and Azure Synapse.
The true value of data comes from the insights gained from data that is often siloed and spans across structured, semi-structured, and unstructured storage formats in terabytes and petabytes. Data mining helps companies to gather reliable information, make informed decisions, improve churn rate and increase revenue.
Every company could benefit from a data-first strategy, but without effective data architecture in place, companies fail to achieve data-first status.
For example, a company’s Sales & Marketing team needs data to optimize cross-sell and up-sell channels, while its product teams want cross-domain data exchange for analytics purposes. The entire organization wishes there was a better way to source and manage the data for its needs like real-time streaming and near-real-time analytics. To address the data needs of the various teams, the company needs a paradigm shift to fast adoption of Data Mesh Architecture, which should be scalable & elastic.
Data Mesh architecture is a shift both in technology as well as in organization, processes, and people.
Before we dive into Data Mesh Architecture, let’s understand its 4 core principles:
- Domain-oriented decentralized data ownership and architecture
- Data as a product
- Self-serve data infrastructure as a platform
- Federated computational governance
Big data is about Volume, Velocity, Variety & Veracity. The first principle of Data mesh is founded on decentralization and distribution of responsibility to the SME\Domain Experts who own the big data framework.
This diagram articulates the 4 core principles of Data Mesh and the distribution of responsibility at a high level.
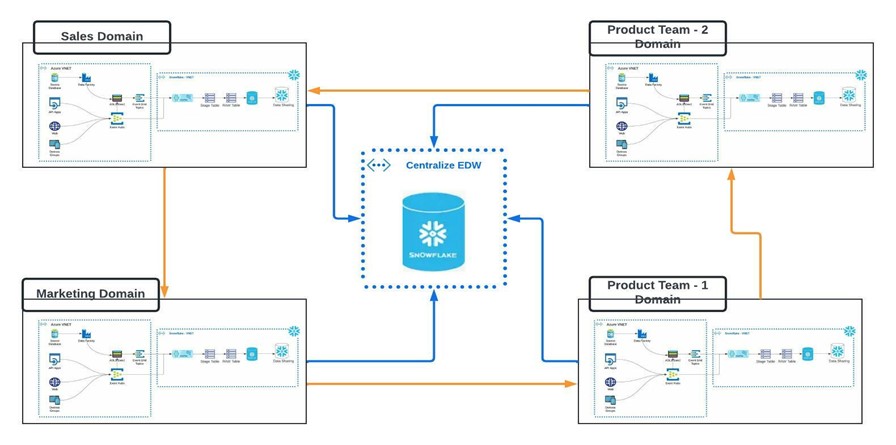
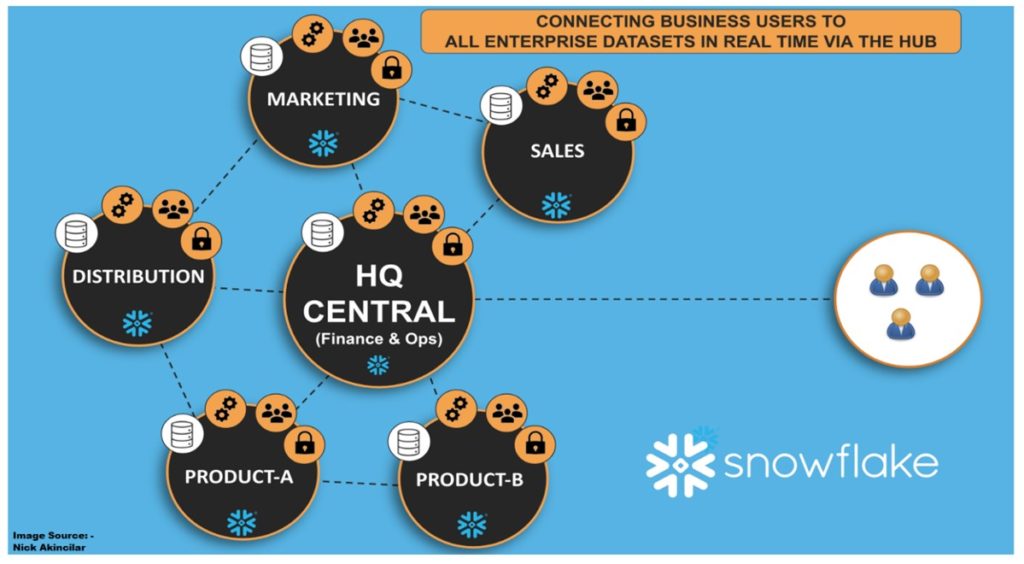
Each Domain data is decentralized in its own data warehouse cloud. This model applies to all data warehouse clouds, such as Snowflake, Azure Synapse, and AWS Redshift.
A cloud data warehouse is built on top of a multi-cloud infrastructure like AWS, Azure, and Google Cloud Platform (GCP), which allows compute and storage to scale independently. These data warehouse products are fully managed and provide a single platform for data warehousing, data lakes, data science team and to provide data sharing for external consumers.
As shown below, data storage is backed by cloud storage from AWS S3, Azure Blob, and Google, which makes Snowflake highly scalable and reliable. Snowflake is unique in its architecture and data sharing capabilities. Like Synapse, Snowflake is elastic and can scale up or down as the need arises.
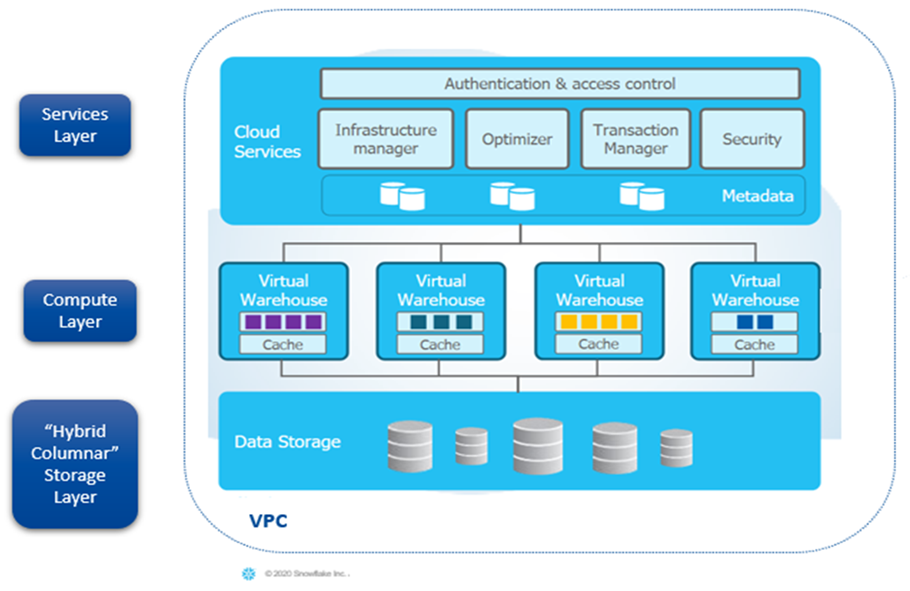
From legacy monolithic data architecture to more scalable & elastic data modeling, organizations can connect decentralized enriched and curated data to make an informed decision across departments. With Data Mesh implementation on Snowflake, Azure Synapse, AWS Redshift, etc., organizations can strike the right balance between allowing domain owners to easily define and apply their own fine-grained policies and having centrally managed governance processes.
Additional resources:
- https://martinfowler.com/articles/data-mesh-principles.html
- https://www.snowflake.com/blog/empower-data-teams-with-a-data-mesh-built-on-snowflake/
- Kopius Cloud Migration and Cloud Services
- How to Develop a Data Retention Policy
- The Right Data Retention Policy for Your Organization
- Let’s Talk About Unified Data Governance
- Using Data to Improve Patient Outcomes
