Por Yuri Brigance
¿Qué es el aprendizaje profundo?
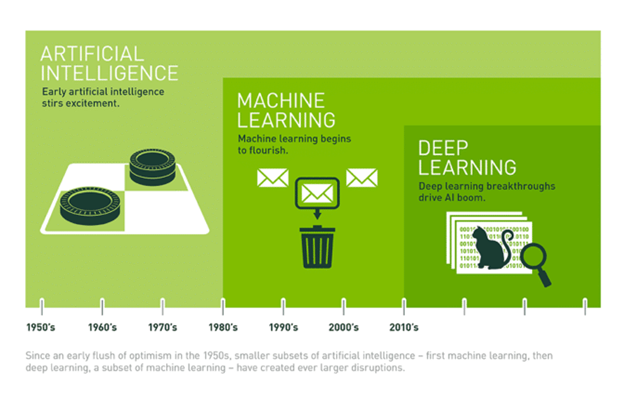
El aprendizaje profundo es un subconjunto del Machine Learning en el que algoritmos inspirados en el cerebro humano aprenden a partir de grandes cantidades de datos. Las máquinas utilizan esos algoritmos para realizar repetidamente una tarea de modo que puedan mejorar gradualmente los resultados. El proceso incluye capas profundas de análisis que permiten un aprendizaje progresivo. El aprendizaje profundo forma parte del continuo de la inteligencia artificial y está dando lugar a avances en el Machine Learning que son creativos, emocionantes y, a veces, sorprendentes. Este gráfico publicado por Nvidia.com ofrece una explicación simplificada del lugar que ocupa el aprendizaje profundo en la progresión del avance de la inteligencia artificial.

El aprendizaje profundo tiene múltiples usos comerciales. He aquí un ejemplo: Usted es un fabricante y los distintos departamentos de la fábrica se comunican mediante formularios de órdenes de trabajo. Se trata de formularios en papel escritos a mano que luego se introducen manualmente en el sistema de gestión de operaciones (OMS). Sin el Machine Learning, tendría que contratar y formar a personas para que introdujeran los datos manualmente. Eso es caro y propenso a errores. Una opción mejor sería escanear los formularios y utilizar ordenadores para realizar el reconocimiento óptico de caracteres (OCR). Esto permite a tus trabajadores seguir utilizando un proceso con el que están familiarizados, al tiempo que extraen automáticamente los datos relevantes y los ingieren en su OMS en tiempo real. Con el Machine Learning y el aprendizaje profundo, el costo es de una fracción de céntimo por imagen. Además, los modelos de análisis predictivo pueden proporcionar información actualizada sobre el rendimiento del proceso, la eficiencia y los cuellos de botella, lo que le da una visibilidad significativamente mejor de su operación de fabricación. Es posible que descubra, como le ocurrió a uno de nuestros clientes, que determinados equipos están infrautilizados durante gran parte del día, lo cual es solo un ejemplo de los tipos de mejoras de eficiencia y ahorros de costos que permite el ML.
¿Cuáles son las tecnologías y los marcos que permiten el aprendizaje profundo?
Aunque existen varias soluciones tecnológicas en el mercado para permitir el aprendizaje profundo, las dos que más nos llaman la atención ahora mismo son PyTorch y TensorFlow. Son igual de populares y actualmente dominan el mercado. También hemos analizado Caffe y Keras, que son alternativas algo menos populares pero relevantes. Dicho esto, voy a centrarme en PyTorch y TensorFlow porque son los líderes del mercado en la actualidad. Para ser transparentes, no está claro que lideren el mercado porque sean necesariamente mejores que las otras opciones. TensorFlow es un producto de Google, lo que significa que TensorFlow se beneficia de la influencia de Google en el mercado y de tus tecnologías integradas. TensorFlow tiene mucha compatibilidad entre plataformas. Está bien soportado en dispositivos móviles, edge computing y navegadores web. Por su parte, PyTorch es un producto de Facebook, que ha invertido significativamente en Machine Learning. PyTorch se creó como el marco de Machine Learning nativo de Python, y ahora incluye API de C++, lo que le da un impulso en el mercado y la paridad de características con TensorFlow.
Despliegue en la periferia
¿Qué pasa con desplegar tus modelos en el borde? Mi experiencia con las cargas de trabajo de ML en los bordes comenzó hace algún tiempo, cuando necesité poner en marcha un modelo en un dispositivo Raspberry Pi de baja potencia. En ese momento, el proceso de inferencia utilizaba toda la capacidad disponible de la CPU y sólo podía procesar datos una vez cada dos segundos. En aquella época, sólo se disponía de una CPU de baja potencia y poca RAM, entonces los modelos tenían que podarse, cuantizarse y reducirse disminuyendo la precisión de la predicción. Había que instalar controladores y dependencias para una arquitectura de CPU específica, y todo el proceso era bastante complicado y lento.
Hoy en día, la CPU no es el único dispositivo de cálculo de borde, ni el más adecuado para la tarea. Hoy en día disponemos de GPU (por ejemplo, NVIDIA Jetson), unidades de procesamiento de sensores (TPU), unidades de procesamiento de visión (VPU) e incluso matrices de puertas programables en campo (FPGA) capaces de ejecutar cargas de trabajo de ML. Con tantas arquitecturas diferentes, y las nuevas que salen con regularidad, no querrás arrinconarte y estar atado a una pieza específica de hardware que podría quedar obsoleta dentro de un año. Aquí es donde entran en juego ONNX y OpenVINO. Debo señalar que Valence es miembro del programa Partner Alliance de Intel y tiene amplios conocimientos de OpenVINO.
ONNX Runtime es de Microsoft. ONNX es similar a una "máquina virtual" para tus modelos preentrenados. Una forma de utilizar ONNX es entrenar el modelo como lo harías normalmente, por ejemplo utilizando TensorFlow o PyTorch. Las herramientas de conversión pueden convertir los pesos del modelo entrenado al formato ONNX. ONNX admite varios "proveedores de ejecución", que son dispositivos como la CPU, la GPU, la TPU, la VPU y la FPGA. El tiempo de ejecución divide y paraleliza de forma inteligente la ejecución de las capas de tu modelo entre las diferentes unidades de procesamiento disponibles. Por ejemplo, si tienes una CPU multinúcleo, el motor de ejecución de ONNX puede ejecutar ciertas ramas de tu modelo en paralelo utilizando varios núcleos. Si agregas un Neural Compute Stick a tu proyecto, podes usarlo para ejecutar partes de tu modelo. Esto acelera la inferencia.
OpenVINO es un conjunto de herramientas gratuitas que facilita la optimización de un modelo de aprendizaje profundo a partir de un marco de trabajo y su despliegue mediante un motor de inferencia en hardware compatible. Tiene dos versiones, una de código abierto y otra compatible con Intel. OpenVINO es un "proveedor de ejecución" para ONNX, lo que significa que permite desplegar un modelo ONNX en cualquier dispositivo compatible (¡incluso FPGA!) sin necesidad de escribir código específico de plataforma o compilación cruzada. Juntos, ONNX y OpenVINO ofrecen la posibilidad de ejecutar cualquier modelo en cualquier combinación de dispositivos informáticos. Ahora es posible desplegar modelos complejos de detección de objetos, e incluso de segmentación, en dispositivos como humildes cámaras web equipadas con una económica VPU integrada. Al igual que un pulpo tiene múltiples "cerebros" en tus tentáculos y cabeza, su sistema puede tener múltiples puntos de inferencia de bordes sin necesidad de ejecutar todos los modelos en un único nodo central o transmitir datos sin procesar a la nube.
Gracias a todas estas tecnologías, podemos desplegar modelos de Machine Learning y programas de aprendizaje profundo en dispositivos de baja potencia, a menudo sin necesidad siquiera de conexión a Internet. Hasta utilizando estos dispositivos de baja potencia, los proyectos de aprendizaje profundo están produciendo resultados inteligentes en los que las máquinas aprenden a identificar personas, animales y otros objetos dinámicos y llenos de matices.
¿Qué debes hacer con esta información?
Depende de quién esté leyendo. Si eres un empresario u operador que siente curiosidad por Machine Learning y el aprendizaje profundo, lo más importante es que cualquier científico de datos con el que trabajes domine estas tecnologías.
Si eres científico de datos, considera estas tecnologías como iuna habilidad mprescindible.
