By Yuri Brigance
What is deep learning?
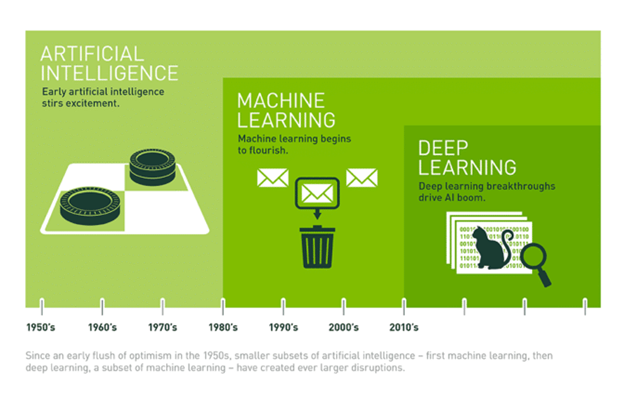
Deep learning is a subset of machine learning where algorithms inspired by the human brain learn from large amounts of data. Machines use those algorithms to repeatedly perform a task so it can gradually improve outcomes. The process includes deep layers of analysis that enable progressive learning. Deep learning is part of the continuum of artificial intelligence and is resulting in breakthroughs in machine learning that are creative, exciting, and sometimes surprising. This graphic published by Nvidia.com provides a simplified explanation of deep learning’s place in the progression of artificial intelligence advancement.

Deep learning has an array of commercial uses. Here’s one example: You are a manufacturer and different departments on the factory floor communicate via work order forms. These are hand-written paper forms which are later manually typed into the operations management system (OMS). Without machine learning, you would hire and train people to perform manual data entry. That’s expensive and prone to error. A better option would be to scan your forms and use computers to perform optical character recognition (OCR). This allows your workers to continue using a process they are familiar with, while automatically extracting the relevant data and ingesting it into your OMS in real-time. With machine learning and deep learning, the cost is a fraction of a cent per image. Further, predictive analytics models can provide up-to-date feedback about process performance, efficiency, and bottlenecks, giving you significantly better visibility into your manufacturing operation. You might discover, as one of our customers did, that certain equipment is under-utilized for much of the day, which is just one example of the types of “low hanging fruit” efficiency improvements and cost savings enabled by ML.
What are the technologies and frameworks that enable Deep Learning?
While there are several technology solutions on the market to enable deep learning, the two that rise to the top for us right now are PyTorch and TensorFlow. They are equally popular, and currently dominate the marketplace. We’ve also taken a close look at Caffe and Keras, which are slightly less popular but still relevant alternatives. That said, I’m going to focus on PyTorch and TensorFlow because they are market leaders today. To be transparent, it’s not clear that they are leading the market because they are necessarily better than the other options. TensorFlow is a Google product, which means that TensorFlow benefits from Google’s market influence and integrated technologies. TensorFlow has a lot of cross-platform compatibility. It is well-supported on mobile, edge computing devices, and web browsers. Meanwhile, PyTorch is a Facebook product, with Facebook being significantly invested in machine learning. PyTorch was built as the native Python machine learning framework, and now includes C++ APIs, which gives it a market boost and feature parity with TensorFlow.
Deploying to the Edge
What about deploying your models to the edge? My experience with edge ML workloads started a while back when I needed to get a model running on a low-powered Raspberry Pi device. At the time the inference process used all the available CPU capacity and could only process data once every two seconds. Back in those days you only had a low-powered CPU and not that much RAM, so the models had to be pruned, quantized, and otherwise slimmed down at the expense of reducing prediction accuracy. Drivers and dependencies had to be installed for a specific CPU architecture, and the entire process was rather convoluted and time consuming.
These days the CPU isn’t the only edge compute device, nor the best suited to the task. Today we have edge GPUs (ex: NVIDIA Jetson), Tensor Processing Units (TPU), Vision Processing Units (VPU), and even Field-Programmable Gate Arrays (FPGA) which are capable of running ML workloads. With so many different architectures, and new ones coming out regularly, you wouldn’t want to engineer yourself into a corner and be locked to a specific piece of hardware which could become obsolete a year from now. This is where ONNX and OpenVINO come in. I should point out that Valence is a member of Intel’s Partner Alliance program and has extensive knowledge of OpenVINO.
ONNX Runtime is maintained by Microsoft. ONNX is akin to a “virtual machine” for your pre-trained models. One way to use ONNX is to train the model as you normally would, for example using TensorFlow or PyTorch. Conversion tools can convert the trained model weights to the ONNX format. ONNX supports a number of “execution providers” which are devices such as the CPU, GPU, TPU, VPU, and FPGA. The runtime intelligently splits up and parallelizes the execution of your model’s layers among the different processing units available. For example, if you have a multi-core CPU, the ONNX runtime may execute certain branches of your model in parallel using multiple cores. If you’ve added a Neural Compute Stick to your project, you can run parts of your model on that. This greatly speeds up inference!
OpenVINO is a free toolkit facilitating the optimization of a deep learning model from a framework and deployment using an inference engine onto compatible hardware. It has two versions including an opensource version and one that is supported by Intel. OpenVINO is an “execution provider” for ONNX, which means it allows you to deploy an ONNX model to any compatible device (even FPGA!) without writing platform-specific code or cross-compiling. Together ONNX and OpenVINO provide the ability to run any model on any combination of compute devices. It is now possible to deploy complex object detection, and even segmentation models on devices like humble webcams equipped with an inexpensive onboard VPU. Just like an octopus has multiple “brains” in its tentacles and head, your system can have multiple edge inference points without the need to execute all models on a single central node or stream raw data to the cloud.
Thanks to all these technologies, we can deploy machine learning models and deep learning programs on low powered devices, often without even requiring an internet connection. And even using these low powered devices, the deep learning projects are producing clever results where the machines learn to identify people, animals, and other dynamic and nuanced objects.
What should you do with this information?
This depends on who is reading this. If you are a business owner or operator who is curious about machine learning and deep learning, your key takeaway is that any data scientist you work with should have a mastery of these technologies.
If you are a data scientist, consider these technologies to be must-haves on your skill inventory.
JumpStart Deep Learning for Your Business
Kopius supports businesses seeking to govern and utilize AI and ML to build for the future. We’ve designed a program to JumpStart your customer, technology, and data success.
Tailored to your needs, our user-centric approach, tech smarts, and collaboration with your stakeholders, equip teams with the skills and mindset needed to:
- Identify unmet customer, employee, or business needs
- Align on priorities
- Plan & define data strategy, quality, and governance for AI and ML
- Rapidly prototype data & AI solutions
- And, fast-forward success
Partner with Kopius and JumpStart your future success.
Related Services:
Additional Resources:
