Por Danny Vally
¿Ha actualizado últimamente el viaje de datos de su organización? Vivimos en la era del Zettabyte, porque el volumen, la velocidad y la variedad de los activos de datos que gestionan las empresas son grandes y cada vez mayores.

Los datos son cada vez más complicados y están más fragmentados. Los datos actuales son más complejos que los que gestionaba una empresa típica hace sólo veinte años. Incluso las pequeñas empresas manejan grandes conjuntos de datos procedentes de fuentes dispares cuyo procesamiento puede resultar complicado. Cada conjunto de datos puede tener su propia estructura, tamaño, lenguaje de consulta y tipo.
Los tipos de datos también están cambiando rápidamente. Lo que antes se gestionaba en hojas de cálculo ahora exige sistemas automatizados, datos de máquinas, datos de redes sociales, datos de IoT, datos de clientes y mucho más.
Existen ventajas económicas reales para las empresas que aprovechan la oportunidad de los datos invirtiendo en transformación digital (a menudo empezando por trasladar los datos a la nube). Las empresas que toman el control de los datos superan a la competencia:
- 40% más de ingresos por empleado
- 50% más de ingresos netos medios sobre ingresos
- 100 millones de dólares anuales de ingresos de explotación adicionales
Entre las situaciones más habituales que motivan las inversiones basadas en datos se incluyen las siguientes:
- Comprender y predecir el comportamiento de los clientes en tiempo real
- Reduzca costos y libere recursos simplificando el análisis de datos
- Explorar nuevos modelos de negocio encontrando nuevas relaciones en los datos
- Elimine los gastos sorpresa e innecesarios
- Recopile y unifique datos para comprender mejor su negocio
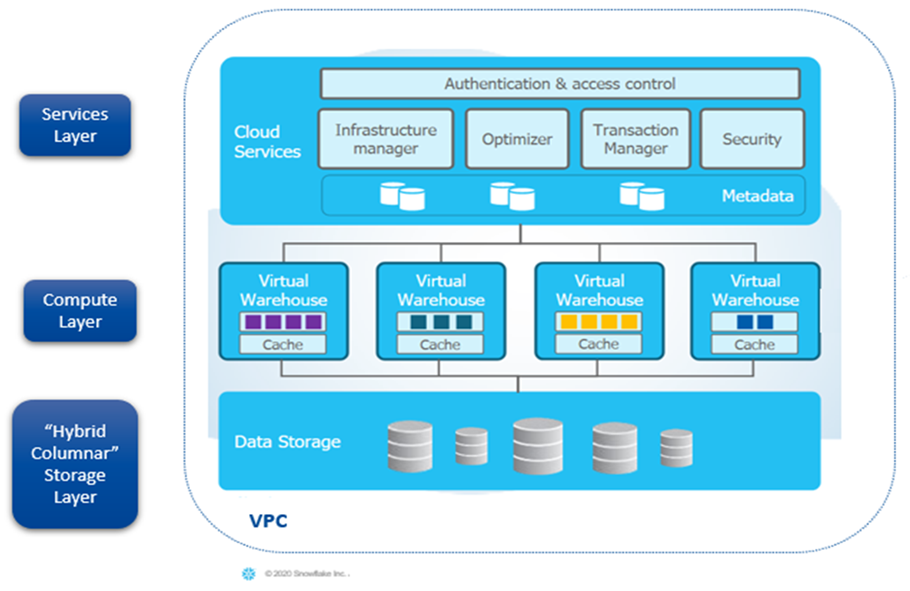
Una estrategia de datos es más que una herramienta, un cuadro de mandos o un informe. Una estrategia de datos madura para cualquier empresa incluye una hoja de ruta para planificar la arquitectura, migración, integración y gestión de los datos de la empresa. La planificación de la gobernanza para garantizar la seguridad, integridad, acceso, calidad y protección de los datos permitirá a la empresa escalar.
Esa hoja de ruta también puede incluir la incorporación de la inteligencia artificial y el Machine Learning, que da rienda suelta al análisis predictivo, el aprendizaje profundo y las redes neuronales. Aunque antes se consideraban herramientas solo al alcance de las empresas más grandes del mundo, la IA y el ML se están implantando con mucho éxito incluso en pequeñas y medianas empresas.
Trabajamos con las organizaciones a lo largo de su viaje de datos, ayudándolas a establecer dónde están, adónde quieren ir y qué quieren conseguir.
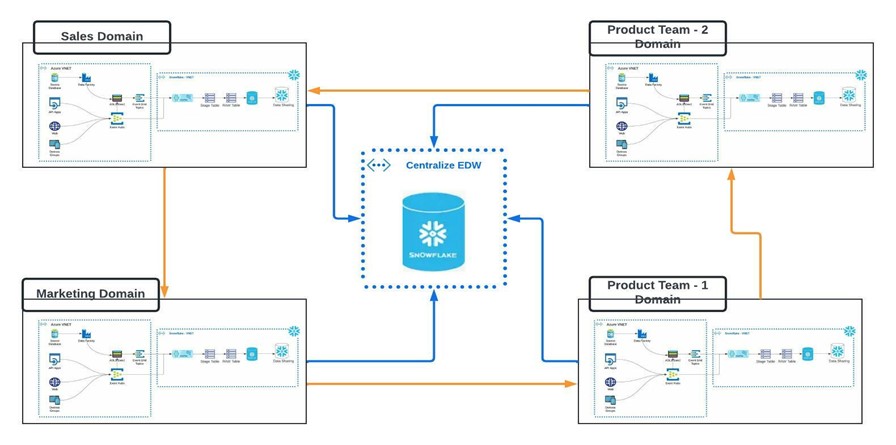
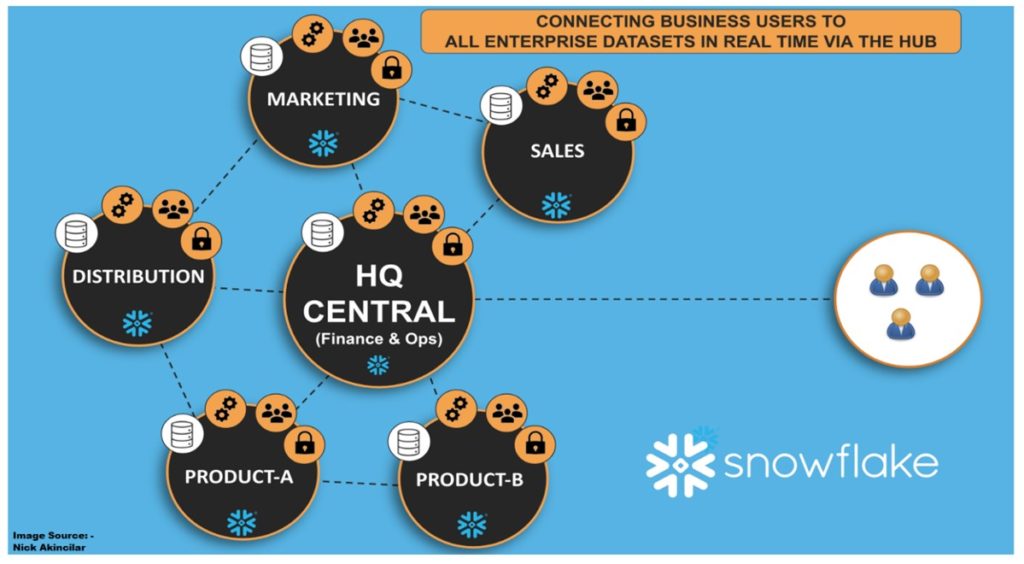
Un viaje de datos suele empezar por comprender las fuentes de datos y organizarlos. Muchas organizaciones tienen múltiples fuentes de datos, por lo que crear un almacén de datos común es un punto de partida importante. Una vez organizados los datos, podemos obtener información de los mismos mediante informes y visualización, lo que permite comprender en tiempo real las métricas clave. Garantizar la gobernanza de los datos y la confianza a la hora de compartirlos es otro paso importante, que a menudo se apoya en la seguridad. Por último, los datos avanzados pueden utilizar la inteligencia artificial y el Machine Learning para buscar tendencias en los datos o predecir comportamientos y extraer nuevas perspectivas. Al comprender en qué punto del recorrido de los datos se encuentra su organización, puede empezar a visualizar el siguiente paso.
Recursos adicionales:
- Prepara tu política de conservación de datos para el éxito
- Arquitectura de data mesh en almacenes de datos basados en la nube
- Migración a la nube y servicios en la nube
- Utilizar los datos para mejorar los resultados de los pacientes
- Informe Databricks: El almacén de datos se une a los lagos de datos