The core of future-proofing your business lies in the incorporation of cutting-edge technological trends and strategic digitization of your business operations. Combining new, transformative solutions with tried-and-true business methods is not only a practical approach but an essential one when competing in this digital age. Using the latest digital transformation trends as your guide, start envisioning the journey of future-proofing your business in order to unlock the opportunities of tomorrow.
#1 Personalization
The importance of personalized customer experiences should not be understated. More than ever, consumers are faced with endless options. To stand out from competitors, businesses must use data and customer behavior insights to curate tailored and dynamic customer journeys that both delight and command their audience. Analyze purchasing history, demographics, web activity, and other data to understand your customer, as well as their likes and dislikes. Use these insights to design customized customer experiences that increase conversion, retention, and ultimately, satisfaction.
#2 Artificial Intelligence
AI is everywhere. From autonomous vehicles and smart homes to digital assistants and chatbots, artificial intelligence is being used in a wide array of applications to improve, simplify, and speed up the tasks of everyday life. For businesses, AI and machine learning have the power to extract and decipher large amounts of data that can help predict trends and forecasts, deliver interactive personalized customer experiences, and streamline operational processes. Companies that lean on AI-driven decisions are propelled into a world of efficiency, precision, automation, and competitiveness.
#3 Sustainability
Enterprises, particularly those in the manufacturing industry, face increasing pressure to act more responsibly and consider environmental, social, and corporate governance (ESG) goals when making business decisions. Digital transformations are one way to support internal sustainable development because they lead to reduced waste, optimized resource use, and improved transparency. With sustainability in mind, businesses can build their data and technology infrastructures to reduce impact. For example, companies can switch to more energy-efficient hardware or decrease electricity consumption by migrating to the cloud.
#4 Cloud Migration
More and more companies are migrating their data from on-premises to the cloud. In fact, by 2027, it is estimated that 50% of all enterprises will use cloud services1. What is the reason behind this massive transition? Cost saving is one of the biggest factors. Leveraging cloud storage platforms eliminates the need for expensive data centers and server hardware, thereby reducing major infrastructure expenditures. And while navigating a cloud migration project can seem challenging, many turn to cloud computing partners to lead the data migration and ensure a painless shift.
Future-Proof Your Business Through Digital Transformation with Kopius
Innovating technology is crucial, or your business will be left behind. Our expertise in technology and business helps our clients deliver tangible outcomes and accelerate growth. At Kopius, we’ve designed a program to JumpStart your customer, technology, and data success.
Kopius has an expert emerging tech team. We bring this expertise to your JumpStart program and help uncover innovative ideas and technologies supporting your business goals. We bring fresh perspectives while focusing on your current operations to ensure the greatest success.
The rise of generative models such as ChatGPT and Stable Diffusion has generated a lot of discourse about the future of work and the AI-assisted workplace. There is tremendous excitement about the awesome new capabilities such technology promises, as well as concerns over losing jobs to automation. Let’s look at where we are today, how we can leverage these new AI-generated text technologies to supercharge productivity, and what changes they may signal to a modern workplace.
That’s the question on everyone’s mind. AI can generate images, music, text, and code. Does this mean that your job as a designer, developer, or copywriter is about to be automated? Well, yes. Your job will be automated in the sense that it is about to become a lot more efficient, but you’ll still be in the driver’s seat.
First, not all automation is bad. Before personal computers became mainstream, taxes were completed with pen and paper. Did modern tax software put accountants out of business? Not at all. It made their job easier by automating repetitive, boring, and boilerplate tasks. Tax accountants are now more efficient than ever and can focus on mastering tax law rather than wasting hours pushing paper. They handle more complicated tax cases, those personalized and tailored to you or your business. Similarly, it’s fair to assume that these new generative AI tools will augment creative jobs and make them more efficient and enjoyable, not supplant them altogether.
Second, generative models are trained on human-created content. This ruffles many feathers, especially those in the creative industry whose art is being used as training data without the artist’s explicit permission, allowing the model to replicate their unique artistic style. Stability.ai plans to address this problem by enabling artists to opt out of having their work be part of the dataset, but realistically there is no way to guarantee compliance and no definitive way to prove whether your art is still being used to train models. But this does open interesting opportunities. What if you licensed your style to an AI company? If you are a successful artist and your work is in demand, there could be a future where you license your work to be used as training data and get paid any time a new image is generated based on your past creations. It is possible that responsible AI creators can calculate the level of gradient updates during training, and the percentage of neuron activation associated to specific samples of data to calculate how much of your licensed art was used by the model to generate an output. Just like Spotify pays a small fee to the musician every time someone plays one of their songs, or how websites like Flaticon.com pay a fee to the designer every time one of their icons is downloaded. Long story short, it is likely that soon we’ll see more strict controls over how training datasets are constructed regarding licensed work vs public domain.
Let’s look at some positive implications of this AI-assisted workplace and technology as it relates to a few creative roles and how this technology can streamline certain tasks.
As a UI designer, when designing web and mobile interfaces you likely spend significant time searching for stock imagery. The images must be relevant to the business, have the right colors, allow for some space for text to be overlaid, etc. Some images may be obscure and difficult to find. Hours could be spent finding the perfect stock image. With AI, you can simply generate an image based on text prompts. You can ask the model to change the lighting and colors. Need to make room for a title? Use inpainting to clear an area of the image. Need to add a specific item to the image, like an ice cream cone? Show AI where you want it, and it’ll seamlessly blend it in. Need to look up complementary RGB/HEX color codes? Ask ChatGPT to generate some combinations for you.
Will this put photographers out of business? Most likely not. New devices continue to come out, and they need to be incorporated into the training data periodically. If we are clever about licensing such assets for training purposes, you might end up making more revenue than before, since AI can use a part of your image and pay you a partial fee for each request many times a day, rather than having one user buy one license at a time. Yes, work needs to be done to enable this functionality, so it is important to bring this up now and work toward a solution that benefits everyone. But generative models trained today will be woefully outdated in ten years, so the models will continue to require fresh human-generated real-world data to keep them relevant. AI companies will have a competitive edge if they can license high-quality datasets, and you never know which of your images the AI will use – you might even figure out which photos to take more of to maximize that revenue stream.
Software engineers, especially those in professional services frequently need to switch between multiple programming languages. Even on the same project, they might use Python, JavaScript / TypeScript, and Bash at the same time. It is difficult to context switch and remember all the peculiarities of a particular language’s syntax. How to efficiently do a for-loop in Python vs Bash? How to deploy a Cognito User Pool with a Lambda authorizer using AWS CDK? We end up Googling these snippets because working with this many languages forces us to remember high-level concepts rather than specific syntactic sugar. GitHub Gist exists for the sole purpose of offloading snippets of useful code from local memory (your brain) to external storage. With so much to learn, and things constantly evolving, it’s easier to be aware that a particular technique or algorithm exists (and where to look it up) rather than remember it in excruciating detail as if reciting a poem. Tools like ChatGPT integrated directly into the IDE would reduce the amount of time developers spend remembering how to create a new class in a language they haven’t used in a while, how to set up branching logic or build a script that moves a bunch of files to AWS S3. They could simply ask the IDE to fill in this boilerplate to move on to solving the more interesting algorithmic challenges.
An example of asking ChatGPT how to use Python decorators. The text and example code snippet is very informative.
For copywriters, it can be difficult to overcome the writer’s block of not knowing where to start or how to conclude an article. Sometimes it’s challenging to concisely describe a complicated concept. ChatGPT can be helpful in this regard, especially as a tool to quickly look up clarifying information about a topic. Though caution is justified as demonstrated recently by Stephen Wolfram, CEO of Wolfram Alpha who makes a compelling argument that ChatGPT’s answers should not always be taken at face value.. So doing your own research is key. That being the case, OpenAI’s model usually provides a good starting point at explaining a concept, and at the very least it can provide pointers for further research. But for now, writers should always verify their answers. Let’s also be reminded that ChatGPT has not been trained on any new information created after the year 2021, so it is not aware of new developments on the war in Ukraine, current inflation figures, or the recent fluctuations of the stock market, for example.
In Conclusion
Foundation models like ChatGPT and Stable Diffusion can augment and streamline workflows, and they are still far from being able to directly threaten a job. They are useful tools that are far more capable than narrowly focused deep learning models, and they require a degree of supervision and caution. Will these models become even better 5-10 years from now? Undoubtedly so. And by that time, we might just get used to them and have several years of experience working with these AI agents, including their quirks and bugs.
There is one important thing to take away about Foundation Models and the future of the AI-assisted workplace: today they are still very expensive to train. They are not connected to the internet and can’t consume information in real-time, in online incremental training mode. There is no database to load new data into, which means that to incorporate new knowledge, the dataset must grow to encapsulate recent information, and the model must be fine-tuned or re-trained from scratch on this larger dataset. It’s difficult to verify that the model outputs factually correct information since the training dataset is unlabeled and the training procedure is not fully supervised. There are interesting open source alternatives on the horizon (such as the U-Net-based StableDiffusion), and techniques to fine-tune portions of the larger model to a specific task at hand, but those are more narrowly focused, require a lot of tinkering with hyperparameters, and generally out of scope for this particular article.
It is difficult to predict exactly where foundation models will be in five years and how they will impact the AI-assisted workplace since the field of machine learning is rapidly evolving. However, it is likely that foundation models will continue to improve in terms of their accuracy and ability to handle more complex tasks. For now, though, it feels like we still have a bit of time before seriously worrying about losing our jobs to AI. We should take advantage of this opportunity to hold important conversations now to ensure that the future development of such systems maintains an ethical trajectory.
JumpStart Your Success Today
Kopius supports businesses seeking to govern and utilize AI and ML to build for the future. We’ve designed a program to JumpStart your customer, technology, and data success.
Tailored to your needs, our user-centric approach, tech smarts, and collaboration with your stakeholders, equip teams with the skills and mindset needed to:
Identify unmet customer, employee, or business needs
Align on priorities
Plan & define data strategy, quality, and governance for AI and ML
This introduces what separates foundation models from regular AI models. We explore the reasons these models are difficult to train and how to understand them in the context of more traditional AI models.
What Are Foundation Models?
What are foundation models, and how are they different from traditional deep learning AI models? The Stanford Institute’s Center of Human-Centered AI defines a foundation model as “any model that is trained on broad data (generally using self-supervision at scale) that can be adapted to a wide range of downstream tasks”. This describes a lot of narrow AI models as well, such as MobileNets and ResNets – they too can be fine-tuned and adapted to different tasks.
The key distinctions here are “self-supervision at scale” and “wide range of tasks”.
Foundation models are trained on massive amounts of unlabeled/semi-labeled data, and the model contains orders of magnitude more trainable parameters than a typical deep learning model meant to run on a smartphone. This makes foundation models capable of generalizing to a much wider range of tasks than smaller models trained on domain-specific datasets. It is a common misconception that throwing lots of data at a model will suddenly make it do anything useful without further effort. Actually, such large models are very good at finding and encoding intricate patterns in the data with little to no supervision – patterns which can be exploited in a variety of interesting ways, but a good amount of work needs to happen in order to use this learned hidden knowledge in a useful way.
The Architecture of AI Foundation Models
Unsupervised, semi-supervised, and transfer learning are not new concepts, and to a degree, foundation models fall into this category as well. These learning techniques trace their roots back to the early days of generative modeling such as Restricted Boltzmann Machines and Autoencoders. These simpler models consist of two parts: an encoder and a decoder. The goal of an autoencoder is to learn a compact representation (known as encoding or latent space) of the input data that captures the important features or characteristics of the data, aka “progressive linear separation” of the features that define the data. This encoding can then be used to reconstruct the original input data or generate entirely new synthetic data by feeding cleverly modified latent variables into the decoder.
An example of a convolutional image autoencoder model architecture is trained to reconstruct its own input, ex: images. Intelligently modifying the latent space allows us to generate entirely new images. One can expand this by adding an extra model that encodes text prompts into latent representations understood by the decoder to enable text-to-image functionality.
Many modern ML models use this architecture, and the encoder portion is sometimes referred to as the backbone with the decoder being referred to as the head. Sometimes the models are symmetrical, but frequently they are not. Many model architectures can serve as the encoder or backbone, and the model’s output can be tailored to a specific problem by modifying the decoder or head. There is no limit to how many heads a model can have, or how many encoders. Backbones, heads, encoders, decoders, and other such higher-level abstractions are modules or blocks built using multiple lower-level linear, convolutional, and other types of basic neural network layers. We can swap and combine them to produce different tailor-fit model architectures, just like we use different third-party frameworks and libraries in traditional software development. This, for example, allows us to encode a phrase into a latent vector which can then be decoded into an image.
Foundation Models for Natural Language Processing
Modern Natural Language Processing (NLP) models like ChatGPT fall into the category of Transformers. The transformer concept was introduced in the 2017 paper “Attention Is All You Need” by Vaswani et al. and has since become the basis for many state-of-the-art models in NLP. The key innovation of the transformer model is the use of self-attention mechanisms, which allow the model to weigh the importance of different parts of the input when making predictions. These models make use of something called an “embedding”, which is a mathematical representation of a discrete input, such as a word, a character, or an image patch, in a continuous, high-dimensional space. Embeddings are used as input to the self-attention mechanisms and other layers in the transformer model to perform the specific task at hand, such as language translation or text summarization. ChatGPT isn’t the first, nor the only transformer model around. In fact, transformers have been successfully applied in many other domains such as computer vision and sound processing.
So if ChatGPT is built on top of existing concepts, what makes it so different from all the other state-of-the-art model architectures already in use today? A simplified explanation of what distinguishes a foundation model from a “regular” deep learning model is the immense scale of the training dataset as well as the number of trainable parameters that a foundation model has over a traditional generative model. An exceptionally large neural network trained on a truly massive dataset gives the resulting model the ability to generalize to a wider range of use cases than its more narrowly focused brethren, hence serving as a foundation for an untold number of new tasks and applications. Such a large model encodes many useful patterns, features, and relationships in its training data. We can mine this body of knowledge without necessarily re-training the entire encoder portion of the model. We can attach different new heads and use transfer learning and fine-tuning techniques to adapt the same model to different tasks. This is how just one model (like Stable Diffusion) can perform text-to-image, image-to-image, inpainting, super-resolution, and even music generation tasks all at once.
Challenges in Training AI Foundation Models
The GPU computing power and human resources required to train a foundation model like GPT from scratch dwarf those available to individual developers and small teams. The models are simply too large, and the dataset is too unwieldy. Such models cannot (as of now) be cost-effectively trained end-to-end and iterated using commodity hardware.
Although the concepts may be well explained by published research and understood by many data scientists, the engineering skills and eye-watering costs required to wire up hundreds of GPU nodes for months at a time would stretch the budgets of most organizations. And that’s ignoring the costs of dataset access, storage, and data transfer associated with feeding the model massive quantities of training samples.
There are several reasons why foundation models like ChatGPT are currently out of reach for individuals to train:
Data requirements: Training a large language model like ChatGPT requires a massive amount of text data. This data must be high-quality and diverse and is typically obtained from a variety of sources such as books, articles, and websites. This data is also preprocessed to get the best performance, which is an additional task that requires knowledge and expertise. Storage, data transfer, and data loading costs are substantially higher than what is used for more narrowly focused models.
Computational resources: ChatGPT requires significant computational resources to train. This includes networked clusters of powerful GPUs, and a large amount of memory volatile and non-volatile. Running such a computer cluster can easily reach hundreds of thousands per experiment.
Training time: Training a foundation model can take several weeks or even months, depending on the computational resources available. Wiring up and renting this many resources requires a lot of skill and a generous time commitment, not to mention associated cloud computing costs.
Expertise: Getting a training run to complete successfully requires knowledge of machine learning, natural language processing, data engineering, cloud infrastructure, networking, and more. Such a large cross-disciplinary set of skills is not something that can be easily picked up by most individuals.
Accessing Pre-Trained AI Models
That said, there are pre-trained models available, and some can be fine-tuned with a smaller amount of data and resources for a more specific and narrower set of tasks, which is a more accessible option for individuals and smaller organizations.
Stable Diffusion took $600k to train – the equivalent of 150K GPU hours. That is a cluster of 256 GPUs running 24/7 for nearly a month. Stable Diffusion is considered a cost reduction compared to GPT. So, while it is indeed possible to train your own foundation model using commercial cloud providers like AWS, GCP, or Azure, the time, effort, required expertise, and overall cost of each iteration impose limitations on their use. There are many workarounds and techniques to re-purpose and partially re-train these models, but for now, if you want to train your own foundation model from scratch your best bet is to apply to one of the few companies which have access to resources necessary to support such an endeavor.
Contact Us to JumpStart Your AI Success
Kopius supports businesses seeking to govern and utilize AI and ML to build for the future. We’ve designed a program to JumpStart your customer, technology, and data success.
Tailored to your needs, our user-centric approach, tech smarts, and collaboration with your stakeholders, equip teams with the skills and mindset needed to:
Identify unmet customer, employee, or business needs
Align on priorities
Plan & define data strategy, quality, and governance for AI and ML
Data is big and getting bigger. We’ve tracked six major data-driven trends for the coming year.
Digital analytics data visualization, financial schedule, monitor screen in perspective
Data is one of the fastest-growing and most innovative opportunities today to shape the way we work and lead. IDC predicts that by 2024, the inability to perform data- and AI-driven strategy will negatively affect 75% of the world’s largest public companies. And by 2025, 50% of those companies will promote data-informed decision-making by embedding analytics in their enterprise software (up from 33% in 2022), boosting demand for more data solutions and data-savvy employees.
Here is how data trends will shift in 2023 and beyond:
1. Data Democratization Drives Data Culture
If you think data is only relevant to analysts with advanced knowledge of data science, we’ve got news for you. Data democratization is one of the most important trends in data. Gartner research forecasts that 80% of data-driven initiatives that are focused on business outcomes will become essential business functions by 2025.
Organizations are creating a data culture by attracting data-savvy talent and promoting data use and education for employees at all levels. To support data democratization, data must be exact, easily digestible, and accessible.
Research by McKinsey found that high-performing companies have a data leader in the C-suite and make data and self-service tools universally accessible to frontline employees.
2. Hyper-Automation and Real-Time Data Lower Costs
Real-time data and its automation will be the most valuable big data tools for businesses in the coming years. Gartner forecasts that by 2024, rapid hyper-automation will allow organizations to lower operational costs by 30%. And by 2025, the market for hyper-automation software will hit nearly $860 billion.
3. Artificial Intelligence and Machine Learning (AI & ML) Continue to Revolutionize Operations
The ability to implement AI and ML in operations will be a significant differentiator. Verta Insights found that industry leaders that outperform their peers financially, are more than 2x as likely to ship AI projects, products, or features, and have made AI/ML investments at a higher level than their peers.
AI and ML technologies will boost the Natural Language Processing (NLP) market. NLP enables machines to understand and communicate with us in spoken and written human languages. The NLP market size will grow from $15.7 billion in 2022 to $49.4 billion by 2027, according to research from MarketsandMarkets.
We have seen the wave of interest in OpenAI’s ChatGPT, a conversational language-generation software. This highly-scalable technology could revolutionize a range of use cases— from summarizing changes to legal documents to completely changing how we research information through dialogue-like interactions, says CNBC.
This can have implications in many industries. For example, the healthcare sector already employs AI for diagnosis and treatment recommendations, patient engagement, and administrative tasks.
4. Data Architecture Leads to Modernization
Data architecture accelerates digital transformation because it solves complex data problems through the automation of baseline data processes, increases data quality, and minimizes silos and manual errors. Companies modernize by leaning on data architecture to connect data across platforms and users. Companies will adopt new software, streamline operations, find better ways to use data, and discover new technological needs.
According to MuleSoft, organizations are ready to automate decision-making, dynamically improve data usage, and cut data management efforts by up to 70% by embedding real-time analytics in their data architecture.
5. Multi-Cloud Solutions Optimize Data Storage
Cloud use is accelerating. Companies will increasingly opt for a hybrid cloud, which combines the best aspects of private and public clouds.
Companies can access data collected by third-party cloud services, which reduces the need to build custom data collection and storage systems, which are often complex and expensive.
In the Flexera State of Cloud Report, 89% of respondents have a multi-cloud strategy, and 80% are taking a hybrid approach.
6. Enhanced Data Governance and Regulation Protect Users
Effective data governance will become the foundation for impactful and valuable data.
As more countries introduce laws to regulate the use of various types of data, data governance comes to the forefront of data practices. European GDPR, Canadian PIPEDA, and Chinese PIPL won’t be the last laws that are introduced to protect citizen data.
Gartner has predicted that by 2023, 65% of the world’s population will be covered by regulations like GDPR. In turn, users will be more likely to trust companies with their data if they know it is more regulated.
Valence works with clients to implement a governance framework, find sources of data and data risk, and activate the organization around this innovative approach to data and process governance, including education, training, and process development. Learn more.
What these data trends add up to
As we step into 2023, organizations that understand current data trends can harness data to become more innovative, strategic, and adaptable. Our team helps clients with data assessments, by designing and structuring data assets, and by building modern data management solutions. We strategically integrate data into client businesses, use machine learning and artificial intelligence to create proactive insights, and create data visualizations and dashboards to make data meaningful.
At Kopius, we’ve designed a program to JumpStart your customer, technology, and data success.
JumpStart Your Data Transformation
Our JumpStart program fast-tracks business results and platform solutions. Connect with us today to enhance your customer satisfaction through a data-driven approach, drive innovation through emerging technologies, and achieve competitive advantage. Add our brainpower to your operation by contacting our team to JumpStart your business.
“Technology is an enabler that will be a game changer in shaping society. Women have a role in how that technology is used and how society will be changed.” Aravinda Gollapudi, Head of Platform and Technology at Sage
We sat with Aravinda Gollapudi, Head of Platform and Technology at Sage, a $2B company that provides small and medium-sized businesses with finance, HR, and payroll software. At Sage, she leads a globally disbursed organization of roughly 270 employees across product, technology, release management, program management, and more. Aravinda also rounds out her technical work by serving as a board advisor for Artifcts and Loopr.
We spoke with Aravinda about technology and how women fit into this industry. Here are the highlights of that exchange.
What is your role in technology? What are you doing today?
I create an operating model for platforms, processes, and organizations to combine speed and scale. This drives market leadership and innovative solutions while accelerating velocity through organizational structure. I do this by leading the technology organization for cloud-native financial services for midmarket at Sage while also driving the product roadmap and strategy for platform as a business unit leader.
I also advise, mentor, and partner with CEOs of startup companies as a board advisor around technologies like AI/ML, SAAS, Cloud, Organizational strategy, and business models. I also help bring my network together to drive go-to-market activities.
I have a unique opportunity with my role to drive the convergence of business outcomes and technology/investment enablers by Identifying, blueprinting, and leading solutions to market – for today, tomorrow, and the future.
How did you get started in technology?
I think my inclination toward technology may be attributed to my interest in mathematics. I am old enough to appreciate how personal computers fueled the exponential adoption of technology!
The current generation of technologists have immense computing power at their fingertips, but I started my foray into technology when I had to use UNIX servers to do my work.
Early in my career, I wanted to go into academia and research in physics. I was working on research work in quantum optics after I graduated with my Master’s in Physics. I spent a lot of time with programming models in Fortran language, which is used in scientific computing. Fortran introduced me to computer programming.
My interest in technology got stronger while I was pursuing my second Masters in Computer Engineering. Although I was taking coursework on hardware and software, I gravitated toward software programming.
What can you tell us about the people who paved the way for you? How did mentors factor into your success?
A big part of my career was shaped very early by my parents, who are both teachers. They instilled the importance of learning and hard work. My dad was a teacher and a principal and was a role model in raising the bar on work ethic, discipline, respect, and courage. My mom, through her multiple master’s degrees and pursuit of continual learning, showed us that it was important to keep learning.
Later in my career, I was fortunate to have the support of my managers, mentors, and colleagues. I leveraged them to learn the craft around software but also around organizational design, product strategy, and overall leadership. I am fortunate to have mentors who challenged me to be better and watch for my blindsides. I still lean on them to this day. A few of my mentors include Christine Heckart, Jeff Collins, Himanshu Baxi, Keith Olsen, and Kathleen Wilson. They have been my managers or mentors who gave me candid feedback, motivated me, and helped me grow my leadership skills.
I would be remiss if I didn’t mention the support and encouragement from my husband! He has always pushed me to take on challenges and supported me while we both balanced family and work.
How can we improve tech for women?
If we want to improve tech for women, we must invest in girls in technology. Hiring managers need to overcome unconscious bias and create early career opportunities for girls.
Mentorship is crucial: We need to acknowledge that the learning and career path is often different for women. Having a strong mentor irrespective of gender helps women learn how to deal with situational issues and career development. Women leaders who can take on this mantle to share their experience and mentor rising stars will help those who do not have a straight journey line in their careers.
Given the smaller percentage of women represented in technology, I am happy to see the trend in the recent past elevating this topic at all levels. By becoming mentors, diversity champions can make a real impact on improving the trend.
We need to invest in allyship and mentorship and elevate the importance of gender diversity. For example, with board searches, organizations like 50/50 Women on Boards elevate the value of having gender diversity and work on legislative support. We need more of that or else we leave behind half the population.
What is one thing you wish more people knew to support women in technology?
I wish more people understood the impact of unconscious bias. Most people do not intend to be biased, but human nature makes us lean toward certain decisions or actions. The tech industry would greatly improve if more people took simple steps to avoid their unconscious bias, like making decisions in several settings (avoiding the time of day impact), ensuring that names and accents don’t impact hiring decisions, and investing in diversity.
What’s around the corner in technology? What trends excite you?
There are three significant trends that excite me right now: Artificial Intelligence/Machine Learning, data, and sustainable tech.
We are living in the world of AI Everywhere and there is more to come. Five out of six Americans use AI services daily. I expect AI to keep shaping automation and intelligent interactions, and drive efficiency.
This is also an exciting time to work with data. We are moving towards a hyper-connected digital world, and the old way of doing things required us to harness vast amounts of digital data from siloed sources. The trend is moving toward driving networks and connections that will fuel more complex machine-to-machine interactions. This data connectivity will impact our lives at home, schools, offices, etc., and will dramatically change how we conduct business.
And I am particularly excited about trends in sustainable technology. We will see more investment in technologies that reduce the impact of compute-hungry technology. I’m anticipating an evolution to more environmentally sustainable investments, which will help us reduce the usage of wasteful resources such as data centers, storage, and computing.
What does the tech world need now more than ever?
The tech world needs better data security and more diversity.
Data is highly accessible in our lives (in part thanks to social media), so we need more investment in privacy and security. We already have seen the impact of this need across personal lives, the political landscape, and business.
For too long, we have not invested enough in diversity, so we have a lot of catching up to do. In the world of technology, we are woefully behind in diversity in leadership positions, particularly in the US tech sector where about 20% of technology leadership positions are held by women.
Data is ubiquitous, tools and frameworks are at our fingertips, and technology is covered earlier in schools, so we are seeing a younger starting age for people getting involved in building technology products/applications. We’ve reduced the barrier of entry (languages, frameworks, low code/no-code tools sets) to make it easier to adopt technology without the overhead of complex coursework. With all these improvements, why are we still so behind on diversity? In the US tech sector, 62% of jobs are held by white Americans. Asian Americans hold 20% of jobs. Latinx Americans hold 8% of jobs. Black Americans hold 7% of jobs. Only 26.7% of tech jobs are held by women.
We have the tools and training. Now we need to change the profile of the workforce to include a more diverse community.
What’s one piece of advice that you would share with anyone reading this?
For women who are reading this, I strongly encourage you to avoid self-doubt and gain confidence by arming yourselves with knowledge and mentors. By bringing our best selves forward, we can focus on opportunities and not obstacles. Technology is an enabler that will be a game changer in shaping society. Women have a role in how that technology is used and how society will be changed.
We spoke with Technical Team Leader and Senior Software Engineer, Claudia Rostagnol about women in tech and more. Claudia is based in Uruguay and has been with our organization for three years, working exclusively for a client in the financial sector as a technical team lead. We talked about how the industry is performing for women in technology, and what trends all people in tech need to pay attention to.
Worldwide, women represent 40 percent of the workforce, and only 17 percent of the tech industry workforce comprises women. We operate out of Argentina and throughout Latin America, and according to data provided by Women in Technology, only 16 percent of the people from Argentina who enroll in degrees related to the tech industry are women. And further, only 14 percent of technical roles are filled by women.
Here are highlights from our conversation with Claudia:
What work are you doing for Valence LatAm?
I’ve been working with Valence LatAm’s client, Berxi, for almost 3 years as a technical team lead. Berxi serves the insurance industry, offering policies to small businesses and professionals.
Our goal with Berxi is to migrate a monolithic system into a microservices architecture, while we keep everything working and also adding new features or products. I work with developers to help them build software; with the business analyst and product owner to identify requirements and manage the work; with the architect to define the architecture and design of the software pieces (microservices with a well-defined API – REST and event-driven,) and with the QA team to coordinate testing in different environments and bug fixing with the development team. My role is very dynamic and interesting!
How did you get started in technology?
I became interested in technology when I was just a small 8 year-old-girl in Uruguay, with a kid-friendly programming language called “Logo”. With Logo, I could program the movements of a turtle moving on the screen with very simple instructions. I’ve been interested in computers and programming ever since.
I studied software programming throughout elementary school, mid-school, and high school. Then I found it very natural to go to the Engineering Faculty to become a Computer Science Engineer.
When I finished my engineering degree, I met a few colleagues during an internship in France. One of them became my husband, Daniel De Vera, and another is Pablo Rodriguez-Bocca, who became my master’s degree tutor. We co-founded a small start-up called GoalBit Solutions and worked together for 6 years. I learned and grew a lot (academically and professionally) during that time!
What can you tell us about the people who paved the way for you? How did mentors factor into your success?
I need to recognize my family, especially my parents! They always support me even if they don’t understand this technical world.
My husband helped to pave the way for me to find opportunities at a US company named Vidillion where I started as a Senior Software Engineer. Their CTO at that time, Steve Popper, was a great mentor as well as a very kind person. He taught me a lot about technology and about remote work and the US tech industry. We continue being friends, even living 10.000 km far from each other. Thanks to Steve, I became more confident in my skills and language.
Let’s talk about what’s around the corner in technology. What trends are you seeing?
AI is used more every day and for everything. I’ve been interested in AI throughout my career. It is a very powerful tool, and we need to think about how to use it well. There is a trend toward responsible AI, which is a good thing.
Also, everything happens in the cloud now. Cloud computing powers everything, including our PCs and mobile phones, and everybody is connected and storing/publishing things on the Internet. So, I think there’s a lot happening there: social networks, crypto, mobile apps for everything, remote education, etc.
What tech does the world need now more than ever?
Data Management and Security – When we share our information, thoughts, pictures, videos, and interests, on the internet, we generate data that may be processed and analyzed in different ways and for different purposes like marketing, sales, and connectivity. All this data can be helpful, and at the same time, it can be dangerous if it is not correctly managed and used. We are sharing a lot of information, which can potentially be made public if it’s not protected.I support the call for additional security and regulations.
Cradle-to-cradle hardware manufacturing – The exponential increase in the use of technology is generating technical waste and digital trash. We frequently discard devices to have the latest or more powerful model and that trash is not biodegradable or easily recyclable. The world needs a clear policy on what to do with all that trash.
Claudia is a volleyball player, seen here with a championship cup
Let’s talk about how to improve tech for women. Do you think tech is changing for women?
Tech is changing for women in the sense that we are more accepted now, but we are far from an equitable system, and it is not changing fast enough. I see too many conferences and events about technology where most of the participants or speakers are men. Men are still accessing higher roles and salaries than women. Paternity and maternity leaves are not equal for men and women.
We need a cultural change in the tech industry, which will take time. But we are making progress. It means a lot to me when I see how our company supports women in tech with events like FemIT, and technical webinars where the speakers are women, and even interviews like this.
Several other companies also have internal initiatives to recognize women’s work and to treat us equally to men. However, I still see too many differences in the number of women being promoted to important roles, or the salary we receive for the same role, especially in LATAM.
I still hear stories about women being asked if they are planning to have children as part of their interview process with other organizations. Women are asked invasive questions that men aren’t asked, and that needs to stop. Thankfully our recruiting team and processes are invested in supporting women in tech.
One thing I like in my country (Uruguay) is that the government provides all kids attending public schools with a laptop when they start school. So boys and girls have the same access to technology at home and school. However, we still have cultural/social messages with gendered toys or games that can falsely signal to girls that boys are better than girls for some things and vice versa.
What is the one thing you wish people knew to support women in technology?
People need to know that women are equally capable if we have equal support and opportunities. We have more than technical skills to add to this technical world. We must continue encouraging girls to get involved in tech and science through messages and experiences at home, at school, and in our communities.
Women need mentors and advocates, including men and women. I wish more people understood how much they can change a woman’s life by helping them to grow in this field.
What’s one piece of advice that you’d like to share with anyone reading?
Women are not better or worse at technical jobs. It is just a matter of learning, practicing, and being supported by other industry leaders.
We need to continue working on a more profound social change that makes the world more equitable for women who want to work in technology!
We recently spent some time with Michael Guzzetta, a seasoned retail technology and innovation executive and consultant who has worked with brands such as The Walt Disney Company, Microsoft, See’s Candies, and H-E-B.
Tell me about your background. What brought you to retail?
Like many people, I launched my retail career in high school when I worked in the men’s department at Robinson’s May. I also worked for The Warehouse (music retailer) and was a CSR at Blockbuster video – strangely, I still miss the satisfaction of organizing tapes on shelves.
I ignited my tech career in 2001 when I started working in payment processing and cloud-based tech, and then I returned to retail in 2009 when I joined Disney Store North America, one of the world’s strongest retail brands.
During my tenure at Disney, I had the privilege of working at the intersection of creative, marketing, and mobile/digital innovation. And this is where the innovation bug bit me and kicked off my decades-long work on omnichannel innovation projects. I seek opportunities to test and deploy in-store technology to simplify experiences for customers and employees, increase sales, and drive demand. Since jump-starting this journey at Disney Store, I’ve also helped See’s Candies, Microsoft, and H-E-B to advance their digital transformation through retail innovation.
What are some of the retail technologies that got you started?
I’ve seen it all! I’ve re-platformed eCommerce sites, deployed beacons and push notifications, deployed in-store traffic counting, worked on warehouse efficiency, automated and integrated buyer journeys and omnichannel programs, and more. I recently built a 20k SF innovation lab space to run proofs-of-concept to validate tech, test, and deployment in live environments. Smart checkout, supply chain, inventory management, eCommerce… you name it.
What are the biggest innovation challenges in retail today?
Some questions that keep certain retailers up at night are, “How can we simplify the shopping experience for customers and make it easier for them to check out?”, “How can we optimize our supply chain and inventory operations?”, “How can we improve accuracy for customers shopping online and reduce substitutions and shorts in fulfillment?” and “How can we make it easier and more efficient for personal shoppers to shop curbside and home delivery orders?” Not to mention, “What is the future of retail, and which technologies can help us stay competitive?”
I see potential in several trends to address those challenges, but my top three are:
Artificial Intelligence/Machine Learning – AI will continue to revolutionize retail. It’s permeated most of the technology we use today, whether it’s SAAS or hardware, like smart self-checkout. You can use AI, computer vision, and machine learning to identify products and immediately put them in your basket. AI is embedded in our everyday lives – it powers the smart assistants we use daily, monitors our social media activity, helps us book our travel, and runs self-driving cars, among dozens of other applications. And as a subset of AI, Machine Learning allows models to continue learning and improving, further advancing AI capabilities. I could go on but suffice it to say that the retailer that nails AI first wins.
Computer vision. Computer vision has a sizable opportunity to solve inventory issues, especially for grocery brands. Today, there’s a gap between online inventory and what’s on the shelf since the inventory system can’t keep pace with what’s stocked and on the shelves for personal shoppers, which is frustrating for customers who don’t expect substitutions or out-of-stock deliveries. With the advent of computer vision cameras, you can combine those differences and see what is on the shelf in real-time to inform what is available online accurately. Computer vision-supported inventory management will be vital to creating a truly omnichannel experience. Computer vision also enables smart shopping carts, self-checkout kiosks, loss prevention, and theft prevention. Not to mention Amazon’s use of CV cameras with their Just Walk Out tech in Amazon Go, Amazon Fresh, and specific Whole Foods locations. It has endless applications for retail and gives you the eyes online that you can’t get in stores today.
Robotics. In the last five years, robotics has taken a seismic leap, and a shift has happened, which you can see in massive, automated fulfillment centers like those operated by Amazon, Kroger, and Walmart. A brand can deliver groceries in a region without having a physical store, thanks to robotic fulfillment centers and distribution centers. It’s a game-changer. Robotics has many functions beyond fulfillment in retail, but this application truly stands out.
What is a missed opportunity that more retail brands should take advantage of?
Data. Data is huge, and its importance can’t be understated. It’s a big, missed opportunity for retailers today. Improving data management, governance, and sanitation is a massive opportunity for retailers that want to innovate.
Key opportunity areas around data in retail include customer experience (know your customer), understanding trends related to customer buying habits, and innovation. You can’t innovate at any speed with dirty data.
There’s a massive digital transformation revolution underway among retailers, and they are trying to innovate with data, but they have so much data that it can be overwhelming. They are trying to create data lakes, a single source of truth, and sometimes they can’t work because of disparate data networks. I believe that some of the more prominent retailers will have their data act together in a few years.
“Dirty data” results from companies being around for a long time, so they’ve accrued multiple data sets and cloud providers, and their data hasn’t been merged and cleaned. If you don’t have the right data, you are making decisions based on bad or old data, which could hurt you strategically or literally.
What do you wish more people understood about retail technology and innovation?
Technology will not replace people. In my experience, technology is meant to enhance the human experience, which includes employees. If technology simplifies the process so much that the employees become idle, they are typically trained to manage the technology or cross-trained to grow their careers. Technology isn’t replacing the human experience any time soon, although it is undoubtedly changing the existing work experience – ideally for the better, both for the employees and the bottom line.
Technology doesn’t always lower costs for retailers. Hardware innovation requires significant capital expenses when it’s deployed chain-wide. Amazon’s “Just Walk Out” is impressive technology, but the infrastructure, cloud computing costs, and computer vision cameras are insanely expensive. In 5 years, that may be different, but today it is a loss leader. It’s worth it for Amazon because they can get positive press, demonstrate innovation, and show industry leadership. But Amazon has not lowered its operating costs with “Just Walk Out.” This is just one example, but there are many out there.
Online shopping will not eliminate brick-and-mortar shopping. If the pandemic has taught us anything, online shopping is here to stay – and convenience is extremely attractive to consumers. But I think people will never stop going to stores because people love shopping. The experience you get by tangibly picking something up and engaging with employees in a store location will always be around, even with the advent of the Metaverse.
What are some brands that excite you right now because of how they use technology?
Amazon. What they have been doing with Just Walk Out technology, dash carts, smart shelves, and other IoT technology puts Amazon at the front of the innovation pack. Let’s not forget that they’ve led the way in same or next-day delivery by innovating with their automated fulfillment centers! They have the desire, the resources, and the talent to be the frontrunner for years to come.
Alibaba. This Chinese company is another retailer that uses technology in incredible ways. Their HEMA retail grocery stores are packed with innovation and technology. They have IoT sensors across the stores, electronic shelf labels, facial recognition cameras so you can check out with your face, and robotic kitchens where your order is made and delivered on conveyor belts. They also have conveyors throughout the store, so a personal shopper can shop by zone, then hook bags to be carried to the wareroom for sortation and delivery prep – it’s impressive.
Walmart and Kroger. Both brands’ use of automated fulfillment centers (AFCs) and drone technology (among many others) are pushing the boundaries of grocery retail today. Their AFCs cast a much wider net and have expanded their existing markets, so, for example, we may see Kroger trucks in neighborhoods that don’t have a store in sight.
Home Depot. They have a smart app with 3D augmented reality and robust in-store mapping/wayfinding. Their use of machine learning is also impressive. For example, it helps them better understand what type of projects a customer might be working on based on their browsing and shopping habits.
Sephora. They use beacon technology to bring people with the Sephora app into the store and engage them. They have smart mirrors that help customers pick the right makeup for their skin tone and provide tutorials. Customers can shop directly through smart mirrors or work with an in-store makeup artist.
What advice do you have for retailers that want to invest in technology innovation?
My first piece of advice is to include change management in the project planning from the start.
There are inherent challenges in retail innovation, often due to change management issues. When a company has been around for decades or even more than a century, they operate with well-known, trusted, and often outdated infrastructure. While that infrastructure can’t uphold the company for the next several decades or centuries, there can be a fear of significant change and a deeply rooted preference for existing systems. There can be a fear of job loss because of the misconception that technology will replace people in retail.
Bring those change-resistant people into the innovation process early and often and invite them to be part of the idea generation. Any technology solution needs to be designed with the user’s needs in mind, and this audience is a core user group. Think “lean startup” approach.
My second piece of advice is to devote enough resources to innovation and give the innovation team the power to make decisions. The innovation team should still operate with lean resources, focusing on minimum viable products and proofs of concept, so failures aren’t cost-prohibitive. The innovation team performs best when it has the autonomy to test, learn, and fail as they explore innovative solutions. Then, it reports its findings and recommendations to higher-ups to calibrate and pivot where needed.
In closing, I’d say the key to innovation success is embracing the notion of failure. Failure has value! Put another way; failure is the fast track to learning. Learning what not to do and what to try next can help a retail company to accelerate faster than the competition. Think MVP, stay lean, get validated feedback quickly, and iterate until you have a breakthrough. And always maintain a growth mindset – never stop learning and growing.
JumpStart Your Retail Innovation Success
Innovating technology is crucial, or your business will be left behind. Our expertise in technology and business helps our clients deliver tangible outcomes and accelerate growth. At Kopius, we’ve designed a program to JumpStart your customer, technology, and data success.
Kopius has an expert emerging tech team. We bring this expertise to your JumpStart program and help uncover innovative ideas and technologies supporting your business goals. We bring fresh perspectives while focusing on your current operations to ensure the greatest success.
Have you updated your organization’s data journey lately? We are living in the Zettabyte Era, because the volume, velocity, and variety of data assets being managed by companies are big and getting bigger.
Data is getting more complicated and siloed. Today’s data is more complex than the data a typical business managed just twenty years ago. Even small companies deal with large data sets from disparate sources that can be complicated to process. Each data set may have its own unique structure, size, query language, and type.
The types of data are also changing quickly. What used to be managed in spreadsheets now demands automated systems, machine data, social network data, IoT data, customer data, and more.
There are real economic advantages for companies that take advantage of the data opportunity by investing in digital transformation (often starting by moving data to the cloud). Companies that take control of data outperform the competition:
40% more revenue per employee
50% higher average net income on revenue
$100M in additional operating income annually
Common data journey scenarios that motivate data-driven investments include:
Understand and predict customer behavior in real-time
Cut costs and free up resources with simplified data analysis
Explore new business models by finding new relationships in data
Eliminate surprise and unnecessary expenses
Gather and unify data to better understand your business
A data strategy is more than a single tool, dashboard, or report. A mature data strategy for any business includes a roadmap to plan the company’s data architecture, migration, integration, and management. Building in governance planning to ensure data security, integrity, access, quality, and protection will empower a business to scale.
That roadmap may also include incorporating artificial intelligence and machine learning, which unleashes predictive analytics, deep learning, and neural networks. While these once were understood to be tools available only to the world’s largest businesses, AI and ML are actually being deployed at even small and midsized businesses, with much success.
We work with organizations throughout their data journey by helping to establish where they are, where they want to go, and what they want to achieve.
A data journey usually starts by understanding data sources and organizing the data. Many organizations have multiple data sources, so creating a common data store is an important starting point. Once the data is organized, we can harness insights from the data using reporting and visualization, which enables a real-time understanding of key metrics. Ensuring data governance and trust in sharing data is another important step, which is often supported by security. Lastly, advanced data can use artificial intelligence and machine learning to look for data trends or predict behaviors and extract new insights. By understanding where your organization is in its data journey, you can begin to visualize its next step.
Contact Kopius to JumpStart Your Success Today
At Kopius, we’ve designed a program to JumpStart your customer, technology, and data success.
Tailored to your needs, our user-centric approach, tech smarts, and collaboration with your stakeholders equip teams with the skills and mindset needed to:
Identify unmet customer, employee, or business needs
Align on priorities
Rapidly prototype solutions
And, fast-forward success
Gather your best and brightest business-minded individuals and join our experts for a hands-on workshop that encourages innovation and drives new ideas.
Data is the new black gold in business. In this post, we explore how shifts in technology, organization processes, and people are critical to achieving the vision for a data-driven company that deploys data mesh architecture in cloud-based warehouses like Snowflake and Azure Synapse.
The true value of data comes from the insights gained from data that is often siloed and spans across structured, semi-structured, and unstructured storage formats in terabytes and petabytes. Data mining helps companies to gather reliable information, make informed decisions, improve churn rate and increase revenue.
Every company could benefit from a data-first strategy, but without effective data architecture in place, companies fail to achieve data-first status.
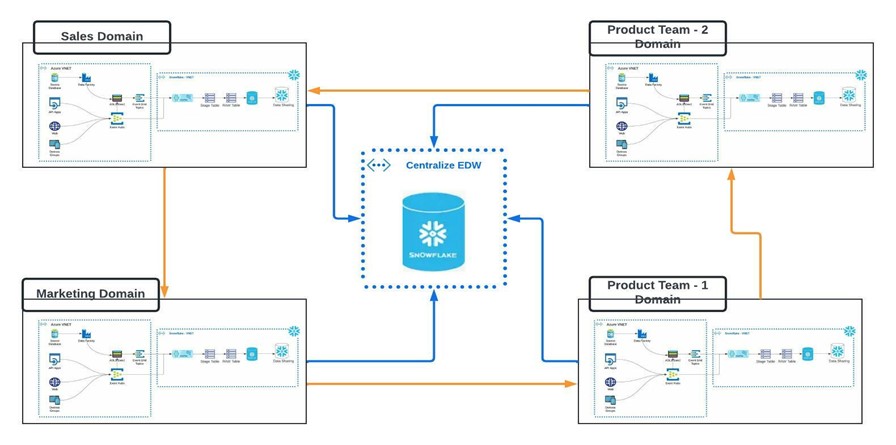
For example, a company’s Sales & Marketing team needs data to optimize cross-sell and up-sell channels, while its product teams want cross-domain data exchange for analytics purposes. The entire organization wishes there was a better way to source and manage the data for its needs like real-time streaming and near-real-time analytics. To address the data needs of the various teams, the company needs a paradigm shift to fast adoption of Data Mesh Architecture, which should be scalable & elastic.
Data Mesh architecture is a shift both in technology as well as in organization, processes, and people.
Before we dive into Data Mesh Architecture, let’s understand its 4 core principles:
Domain-oriented decentralized data ownership and architecture
Data as a product
Self-serve data infrastructure as a platform
Federated computational governance
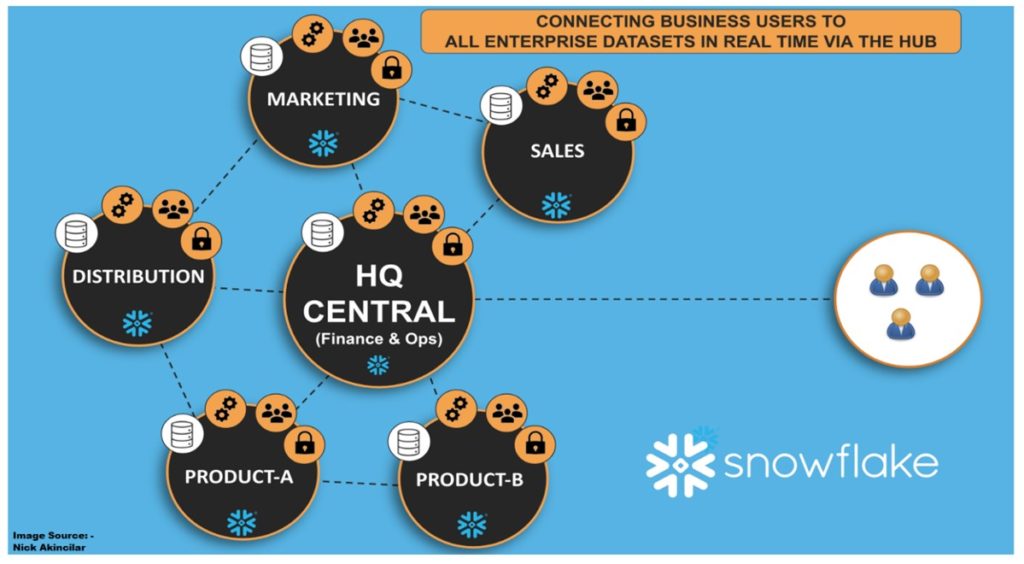
Big data is about Volume, Velocity, Variety & Veracity. The first principle of Data mesh is founded on decentralization and distribution of responsibility to the SME\Domain Experts who own the big data framework.
This diagram articulates the 4 core principles of Data Mesh and the distribution of responsibility at a high level.
Azure: Each team is responsible for its own domain, and data is decentralized and shared with other domains for data exchange and data as a product.Snowflake: Each team is responsible for its own domain, and data is decentralized and shared with other domains for data exchange and data as a product.
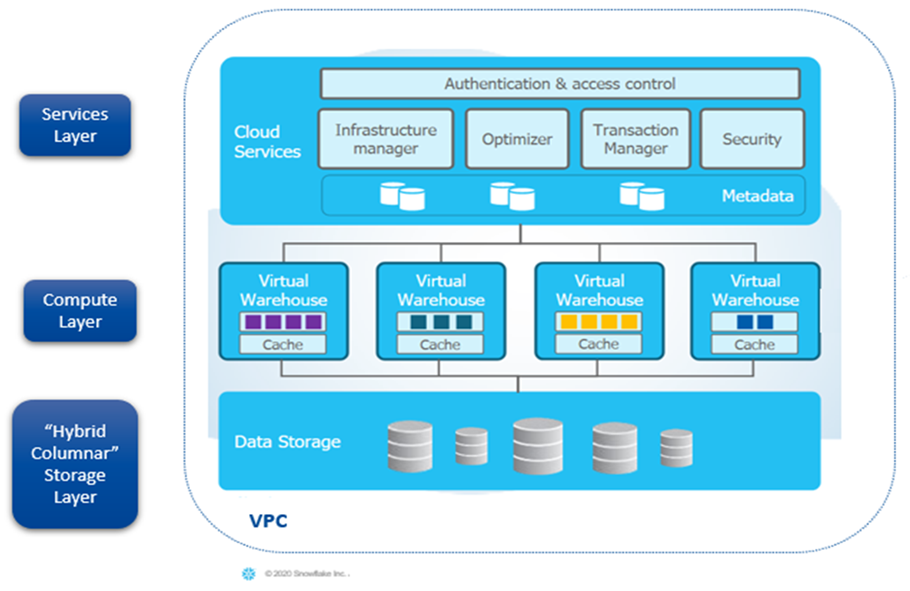
Each Domain data is decentralized in its own data warehouse cloud. This model applies to all data warehouse clouds, such as Snowflake, Azure Synapse, and AWS Redshift.
A cloud data warehouse is built on top of a multi-cloud infrastructure like AWS, Azure, and Google Cloud Platform (GCP), which allows compute and storage to scale independently. These data warehouse products are fully managed and provide a single platform for data warehousing, data lakes, data science team and to provide data sharing for external consumers.
As shown below, data storage is backed by cloud storage from AWS S3, Azure Blob, and Google, which makes Snowflake highly scalable and reliable. Snowflake is unique in its architecture and data sharing capabilities. Like Synapse, Snowflake is elastic and can scale up or down as the need arises.
From legacy monolithic data architecture to more scalable & elastic data modeling, organizations can connect decentralized enriched and curated data to make an informed decision across departments. With Data Mesh implementation on Snowflake, Azure Synapse, AWS Redshift, etc., organizations can strike the right balance between allowing domain owners to easily define and apply their own fine-grained policies and having centrally managed governance processes.
JumpStart Data Success
Innovating technology is crucial, or your business will be left behind. Our expertise in technology and business helps our clients deliver tangible outcomes and accelerate growth. At Kopius, we’ve designed a program to JumpStart your customer, technology, and data success.
Kopius has an expert emerging tech team. We bring this expertise to your JumpStart program and help uncover innovative ideas and technologies supporting your business goals. We bring fresh perspectives while focusing on your current operations to ensure the greatest success.
By joining forces, Kopius and MajorKey offer an even greater set of cloud services for businesses that want to power their digital transformation with cloud technologies.
MajorKey works with clients to migrate business applications to the cloud, and Kopius builds services on the cloud. This is one reason these businesses are such a powerful combined force.
The cloud refers to software and services that run on a (usually) regionally located server owned by the cloud service provider, instead of on an on-premise server owned by a customer. Cloud servers are in data centers all over the world. By using cloud computing, companies don’t have to manage physical servers or run software applications on their own machines.
It’s big business. In fact, one of our partners, AWS contributed 14.5% of revenue to Amazon’s overall business in 2021, which would have operated at a $1.8 billion loss in Q4 without it – and AWS revenue was up nearly 39% compared to 2020.
There are many ways to use and understand the business impact of cloud technology. We are breaking down the distinction between cloud services and cloud migration for you here!
Simply put, cloud migration is what happens when a company moves some or all of its software onto cloud servers.
In other words, cloud migration is moving your software to a managed server operated by the cloud provider; and cloud services are technology solutions built on top of those managed servers. There’s a whole range of capabilities bridging the two.
Let’s take a closer look.
Cloud services range in how much they abstract away from the customer. A good example is Amazon Cognito, which is a user management cloud service. Amazon Cognito has implementations of basic user functions such as login, logout, sessions, and security, so a customer doesn’t have to worry about a deeper technical implementation of these features and can focus on managing users.
Cloud services are so flexible that there are seemingly infinite ways to deploy them for a business. Cloud services are the infrastructure, platforms, and software hosted by cloud providers, and there are three common solutions:
Infrastructure as a service: The renting out of virtual machines and space to customers, while providing a way to remotely manage the resource. When a company migrates to the cloud, they are using this service.
Platforms: Providers like AWS and Azure build specialized software on top of their own cloud hardware and offer the software to customers as a service. These are specialty services and can provide patterns for things such as Data Analysis, Compute, IoT, APIs, Security, Identity, and Containerization. We wrote about Digital Twins in a previous post, which referenced Digital Twin platforms offered by AWS and Azure.
Software as a service (SaaS): Software can be built on top of the platforms offered by the cloud providers. Software developers can also partner with other third parties to provide fully built instances of software that typically come with subscription rates, customer support, and personal configurations of the software. Examples of this include Atlassian Jira and Confluence, Dropbox, Salesforce, and G suite.
These services can be transformative for businesses in general, but it’s not always easy to know the best way for your business to use them. The added benefits to this migration range per case, and here are four examples:
Scalability: Cloud services often offer on demand scaling options that can satisfy unexpected or planned growth. Depending on your product, this can be a lot easier than upgrading on-premise hardware, but not always cheaper.
Cost: Although we expect the costs to be passed to the consumer in some way, the logistics of maintenance and upgrades to the cloud systems is handled by the provider. In many cases this can translate to a huge amount of money saved for the customers.
Performance: Performance-enhancing services like CDNs and regional hosting, when understood and configured properly, can have tangible and positive performance impacts.
Local Management: Being on the cloud means access to the digital portals to manage the services (most times). This creates a lower bar of entry for employees to manage and observe the resources.
Many businesses start their digital transformation journey by migrating infrastructure or applications from on-premises servers to the cloud. Notably, cloud migration can also refer to a situation where a business needs to bring the cloud resources they manage into an on-premises environment. It can also describe a situation where a business moves its data resources from one cloud provider to another.
Cloud migration to use cloud services is a process that presents many upsides, and is worth investigating! The process will add additional complexities – specifically, security and governance will generally be instituted upfront as a base for the rest of the migration. We design and engineer performant, scalable, and maintainable applications that save businesses money, fill in knowledge gaps, and provide users with a positive experience.
Here are two examples of cloud services that we’ve built for clients:
Building cloud applications with AWS lambda: We have bridged the gap between multiple third-party APIs and created new databases that consolidate data and deliver it to a web application. Cloud services remove the need for our clients to interact with these multiple services, which saves them time and money. At the same time, we used AWS Cognito to help our customer manage roles and users in a secure and trusted way. This removed the need for our engineers to write our own user management software, a cumbersome task.
Data pipelines: We identify problems in our customers’ current database providers and migrate data to a more performant and better structured database in cloud-to-cloud migrations.
We will continue to build and migrate while we investigate the future of the cloud. What are the new services and platforms? Who can benefit the most from them? How can we do it right? We will be prepared for the cloud migration and services needed from the real world to the metaverse, and beyond.
JumpStart Your Success Today
Innovating technology is crucial, or your business will be left behind. Our expertise in technology and business helps our clients deliver tangible outcomes and accelerate growth. At Kopius, we’ve designed a program to JumpStart your customer, technology, and data success.
Kopius has an expert emerging tech team. We bring this expertise to your JumpStart program and help uncover innovative ideas and technologies supporting your business goals. We bring fresh perspectives while focusing on your current operations to ensure the greatest success.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.